Ruby Sinatra on AWS Lambda
Article29.11.2018 AWS Lambda announced official Ruby Support. That means we all can build Serverless applications (or FaaS scripts) with the language that we love.
AWS in the same article also provided quite decent step by step manual for creating AWS Lambda functions but also how to run Sinatra application on AWS Lambda with a code sample project AWS Lambda - serverless Sinatra app example
In this article I will explain in more depth how this works and how it is even possible to run Sinatra (and other small Rack applications) on AWS Lambda
Originally I wanted to create step by step Sinatra - AWS Lambda manual from scratch but guys at AWS done really good job with the mentioned example repo. I couldn’t produce anything that would add more value.
AWS Lambda - how it works
Lamda is a product from AWS (Amazon Web Services) in which you run code without provisioning or managing servers. You pay only for the compute time you consume - there is no charge when your code is not running.
I literally copy paste this definition from their website
So what it means is you write Ruby script, you load the code to AWS Lamda and then when you trigger it. That will:
- spin up Lambda function
- run your script code (e.g. write some record to DB, process some payment, send an email)
- spin down Lamda (after some time of inactivity)
Serverless folks will hate me for using the words “spin up”. In reality YOU are not spinning up anything as the AWS Lamda function is Function as a Service (FaaS) therefore provisioning is taken care of by AWS. All you need to do is invoke it. If no availible Lambda is up it will spin up (“cold start”) automatically.
The price of execution depends of how much memory you allocate to the Lambda execution and how long it will took to finish your code execution. But generally we are talking about like $0.00001 per execution (pricing)
Duration is calculated from the time your code begins executing until it returns or otherwise terminates, rounded up to the nearest 100ms. The price depends on the amount of memory you allocate to your function.
If you need to run the same Lambda function simultaneously 10 times you have to spin up 10 separate Lamba invocations of the same functionality.
However next execution of AWS lamda function will be executed on waiting AWS Lambda (no spin up is necessary you just invoke code/params on span-up one that is not performing anything)
- spin up Lambda function
- call handler
#lambda_handler- from this point is when you start being charged $$$ - run your code
- return value - from this point is when you stop being charged
- call handler
#lambda_handler- from this point is when you start being charged $$$ - run your code
- return value - from this point is when you stop being charged
- spin down Lamda (after some time of inactivity)
The important part is that you are not able guarantee that if you load something in the memory for next execution, it will get picked up. So if you load bunch of dependencies/configurations into the memory they may not be there for the next invocation.
Therefore “cold start” of AWS Lambda may take some time if your code is too heavy.
Also this depends on what programming lang you use in AWS Lambda. Java, C# would notice slower cold starts far more than Python or Ruby.
Bare with me I’ll get to the point why all this is important in a minute.
More details about this can be found in articles like AWS Lambda cold starts or keep your lambdas warm
Plugging in API Gateway
AWS Lambda is just a engine. It only executes your Ruby script. There is no routing inside as you would have in Ruby on Rails application.
What you need to do is to plug routing solution to your individual Lambda Functions.
AWS provides another product called AWS API Gateway in which you define what route will call what AWS Lambda / Lambdas
e.g.:
- GET
/users=> calllist_usersAWS Lambda function - POST
/users=> callcreate_userAWS Lambda function and pass the JSON request body to it e.g{"first_name": "Tomas"}
But you can also configure proxy routes with * where anything
(POST/GET/PUT/DELETED can be directed to a particular Lambda Function
So technically speaking you can have
* /users/*pointing to one AWS Lambda* /products/*pointing to another AWS Lambda* /cusstomer_support/*pointing to another AWS Lambda
Sinatra
So now we understand how API Gateway and AWS Lambda works I can finally explain how is it even possible that you can run Sinatra on AWS Lambda?
You need to realize that you are not actually running web-server (or App-server) like you would normally do with Sinatra or Ruby on Rails.
When you for example run rails server in Ruby on Rails project on your laptop you actually start
Puma/Webrick app server that listens on a port (e.g. 3000 or 8080) and
when request hit’s the server/localhost this app server will call the
Rack application == your Ruby code,
Ruby routes -> Ruby controllers -> Ruby Model -> …
Similar way Sinatra works. You call
ruby app.rbyou will start Webrick Ruby server. ->Browser->Webrick->Rack->Sinatra routes & code
Therefore in the AWS Lambda Sinatra example you don’t lunch any App server (no Puma, no Webrick). The AWS API Gateway is your APP server.
You just need to call the Rack part of Sinatra with your AWS Lambda function passing the request params/body from the AWS API Gateway
That’s being done here in the source code (mirror )
I’ll describe the entire flow of the code at the bottom of this article
That Brings us to the main point of how this works:
AWS API Gateway will proxy any/every request to this one AWS Lambda that will spin up and execute one route of the Sinatra application. Once the response is returned to the API Gateway Lambda will die.
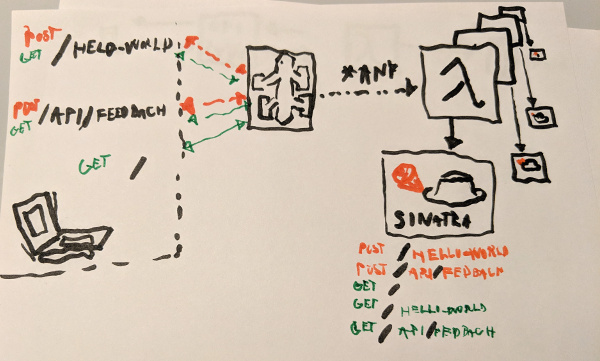
That means if this Sinatra app needs to receive 50 requests, it will spin up 50 AWS Lambda Functions.
And only next requests “may be” executed on loaded up Lambdas with Sinatra dependancies in memory.
If there are 1000 requests concurrently, AWS will try to run 1000 invocations for the same Lambda function. However, if it’s 1000 requests/second, and each request only needs 200 ms to process, there could only be 200 concurrent invocations at any point of time. Reference
Thank you Xiang Shen for pointing this out.
Use case
So is this solution good ?
Well every tool has it’s purpose. You will use hammer to nail a nail to a wall but to fix your laptop hammer would not be the best tool.
Originally this “run your webserver in Lambda” feature was introduced to help web developers to migrate existing microservices to AWS without the need of full rewrite to Lambda scripts
Sinatra is not the first “tiny web server” that AWS Lambda introduced. You can do AWS Lambda Expres JS web apps for quite some time now.
So the feature was introduced more like a migration help HOWEVER when used with caution it can be stable in production for microcervices.
And you can always mix and match with regular serverless flow of simple AWS Functions
e.g.:
post /users/pointing to lambda functionput /users/123pointing to different lambda function* /productspointing to one Sinatra Microservice on AWS Lambda function* /basketpointing to another Sinatra Microservice on AWS Lambda function* /cusstomer_supportpointing to another Sinatra Microservice on AWS Lambda function
This brings us to to next big question:
Can I run Ruby on Rails on AWS Lambda ?
Sinatra is build on top of Rack. Rails is build on top Rack. So there should not be any problem running entire Ruby on Rails project on AWS Lambda right ?

You need to realize that serverless is next level of Microservices. It’s not designed for Monolith Applications. And although Rails can be used to some degree in Microservices it’s primary goal is Monolith ( e.g.: Majestic Monolith by D.H.H)
I have entire 40 min talk about Monolith, Microservices & Serverless Ruby
By definition Rails have lot of tools and dependencies that are freaking awesome in long running Monolith but makes zero sense in Serverless.
If you manage to make AWS Lambda work with Rails you would discover that every request is taking ridiculous amount of time because every request would have to load entire Rails and your code to memory .
You need to have your Lambda functions load up fast otherwise you will have slow response times and pay more than you would with server running 24h a day.
Same would apply for large Sinatra Applications.
If your Sinatra application has 5 - 10 routes and maybe 5 small extra gems then you are fine. If your Sinatra application is a monolith with like 100 routes with 50 dependencies then you will have same problem as with Rails.
So no Rails is not Designed for this. Don’t do it even if you theoretically could.
Full flow of AWS Sinatra Serverless example
We are done with the main article (you don’t need to read this). This section is more for those who want to try out the example repo and learn how it works step by step.
API Gateway is called
During the time this article was being published author of serverless-sinatra-sample pushed support for AWS ALB (application load balacer) commit which is even cooler.
I will update this article as soon as I can
- Browser makes request to
https://xxxxxxxxxx.execute-api.eu-west-1.amazonaws.com/Prod/hello-world - Global AWS recognize subdomain domain
xxxxxxxxxx.execute-api.eu-west-1.amazonaws.comand pass it to your AWS API Gateway product - AWS API Gatway see that you are using the
/Prodpipeline (as you can have /Stage or /Prod) so it will pass the request to theProdstage - In
ProdStage will recognize you are calling/hello-worldnow the project has configured a API Gateway to pass all request*to AWS Lambda executing our Sinatra app. Therefore this Proxy will trigger our Sinatra AWS Lamda for any request (/,/hello-world,/api/feedback) any method (GET,POST,…) - AWS Lamda is executed.
AWS Lambda Execution
AWS lambda calls lambda.rb #handler method which does the following:
- set Rack enviroment variables related to the replication of appserver call
# ...
env = {
"REQUEST_METHOD" => event['httpMethod'],
"SCRIPT_NAME" => "",
"PATH_INFO" => event['path'] || "",
"QUERY_STRING" => event['queryStringParameters'] || "",
"SERVER_NAME" => "localhost",
"SERVER_PORT" => 443,
"rack.version" => Rack::VERSION,
"rack.url_scheme" => "https",
"rack.input" => StringIO.new(event['body'] || ""),
"rack.errors" => $stderr,
}
form this the most important is the setting of the PATH_INFO => what will end up in Sinatra routing and the "rack.input" => what will become our params
- as aleady mentioned we call The Rack application
# ...
status, headers, body = $app.call(env)
# ...
From this point the app/server.rb
- Sinatra will carry on application execution as normal Sinatra webserver. That means it will find the get ‘/hello-world’ route and execute the code.
One important point to mention here is the before block we do at the
top of the file (here)
before do
if request.body.size > 0
request.body.rewind
@params = Sinatra::IndifferentHash.new
@params.merge!(JSON.parse(request.body.read))
end
end
As in first step we were setting the ENV variable rack.input with
the body of API Gateway, Sinatra would not effectively parse the body as
it would be in raw JSON format. That’s why this block will parse the
JSON to hash as would Sinatra normally do with HTTP form params
This will be needed when you do POST /api/feedback
- and finally
lambda.rbwill pass the response of the rack application back to API Gateway via return value here
Links
- Monolith, Microservices & Serverless Ruby Mirror
- https://aws.amazon.com/blogs/compute/announcing-ruby-support-for-aws-lambda/
- https://github.com/aws-samples/serverless-sinatra-sample
- https://www.serverless-ruby.org/
Discussion:
Entire blog website and all the articles can be forked from this Github Repo